В статистике, обработке сигналов и многих других областях под временным рядом понимаются последовательно измеренные через некоторые (зачастую равные) промежутки времени данные. Анализ временных рядов объединяет методы изучения временных рядов, как пытающиеся понять природу точек данных (откуда они взялись? что их породило?), так и пытающиеся построить прогноз. Прогнозирование временных рядов заключается в построении модели для предсказания будущих событий основываясь на известных событий прошлого, предсказания будущих данных до того как они будут измерены. Типичный пример - предсказание цены открытия биржи основываясь на предыдущей её деятельности.
Понятие анализ временных рядов используется для того, чтобы отделить эту задачу от в первую очередь от более простых задач анализа данных (когда нет естественного порядка поступления наблюдений) и, во-вторых, от анализа пространственных данных, в котором наблюдения зачастую связаны с географическим положением. Модель временного ряда в общем смысле отражает идею, что близкие во времени наблюдения будут теснее связаны, чем удалённые. Кроме того, модели временных рядов зачастую используют однонаправленный порядок по времени в том смысле, что значения в ряду выражаются в некотором виде через прошлые значения, а не через последующие (см. обратимость времени).
Методы анализа временных рядов зачастую делят на два класса: анализ в частотной области и анализ во временной области. Первый основывается на спектральном анализе и с недавних пор вейвлетном анализе , и может рассматриваться в качестве не использующих модели методов анализа, хорошо подходящих для исследований на этапе разведки. Методы анализа во временной области также имеют безмодельное подмножество, состоящее из кросс-корреляционного анализа и автокорреляционного анализа, но именно здесь появляются частично и полностью определённые модели временных рядов.
Анализ временных рядов
Существует несколько методов анализа данных, применимых для временных рядов.
Общее исследование
- Визуальное изучение графических представлений временных рядов
- Автокорреляционный анализ для изучения зависимостей
- Спектральный анализ для изучения циклического поведения, не связанного с сезонностью
Описание
- Разделение компонент: тренд, сезонность, медленно и быстро меняющиеся компоненты, циклическая нерегулярность
- Простейшие свойства частных распределений
Прогнозирование и предсказание
- Полноценные статистические модели при стохастическом моделировании для создания альтернативных версий временных рядов, показывающих, что могло бы случиться на произвольных отрезках времени в будущем (предсказание)
- Упрощённые или поноценные статистические модели для описания вероятные значения временного ряда в ближайшем будущем при известных последних значениях (прогноз)
Модели временных рядов
Как показано Боксом и Дженкинсом, модели временных рядов могут иметь различные формы и представлять различные стохастические процессы. При моделировании изменений уровня процесса можно выделить три широких класса имеющих практическую ценность: авторегрессионые модели , интегральные модели и модели скользящего среднего . Эти три класса линейно зависят от предшествующих данных. На их основе построены модели авторегрессионного скользящего среднего (Autoregressive Moving Average , ARMA) и авторегрессионного интегрированного скользящего среднего (Autoregressive Integrated Moving Average , ARIMA). Эти модели в свою очередь обобщает модель авторегрессионного дробноинтегрированного скользящего среднего (autoregressive fractionally integrated moving average , ARFIMA). Расширения моделей на случаи, когда данные представляются не скалярно, а векторно, называют моделями многомерных временных рядов. Для таких моделей в сокращённых названиях появляется буква «v» от слова «vector». Существуют расширения моделей на случай, когда исследуемый временной ряд является ведомым для некоторого «вынуждающего» ряда (который, однако, может не быть причиной возникновения исследуемого ряда). Отличие от многомерного ряда заключается в том, что вынуждающий ряд может быть детерминированным или управляться исследователем, проводящим эксперимент. Для таких моделей в сокращении появляется буква «x» от «exogenous» (экзогенный, вызываемый внешними причинами).
Нелинейная зависимость уровня ряда от предыдущих точек интересна, отчасти из-за возможности генерации хаотических временных рядов. Но главным всё же является то, что опытные исследования указывают на превосходство прогнозов, полученных от нелинейных модлей, над прогнозами линейных моделей.
Среди прочих типов нелинейных моделей временных рядов можно выделить модели, описывающие изменения дисперсии ряда со временем (гетероскедатичность). Такие модели называют моделями авторегрессионной условной гетероскедастичности (AutoRegressive Conditional Heteroscedasticity , ARCH). К ним относится большое количество моделей: GARCH, TARCH, EGARCH, FIGARCH, CGARCH и др. В этих моделях изменения дисперсии связывают с ближайшими предшествующими данными. Противовесом такому подходу является представление локально изменчивой дисперсии, при котором дисперсия может быть смоделирована зависящей от отдельного меняющегося со временем процесса, как в бистохастических моделях.
В последнее время значительное внимание снискали исследования в области безмодельного анализа и методы, основанные на вейвлетных преобразованиях (например локально стационарные вейвлеты) в частности. Методы многомасштабного анализа разлагают заданный временной ряд на составные части, чтобы показать зависимость от времени с разным масштабом.
Обозначения
Существует большое число вариантов обозначения временных рядов. Одним из типичных является , обозначающее ряд с натуральными индексами. Другое стандартное представление:
Предположения
Существуют две группы предположений, в условиях которых строится большинство теорий:
- Стационарность процесса
- Эргодичность
Идея стационарности трактуется в широком смысле, охватывая две основных идеи: строгая стационарность и стационарность ворого порядка (стационарность в широком смысле). На основании этих предложений могут быть построены и модели, и приложения, хотя модели в дальнейшем могут рассматриваться как частично заданные.
Анализ временного ряда может проводиться и когда ряд сезонно стацонарен или нестационарен.
Модели
,где - источник случайность, белый шум. Белый шум имеет следующие свойства.
Введение
В данной главе рассматриваются задачи описания упорядоченных данных, полученных последовательно (во времени). Вообще говоря, упорядоченность может иметь место не только во времени, но и в пространстве, например, диаметр нити как функция её длины (одномерный случай), значение температуры воздуха как функция пространственных координат (трёхмерный случай).
В отличие от регрессионного анализа, где порядок строк в матрице наблюдений может быть произвольным, во временных рядах важна упорядоченность, а следовательно, интерес представляет взаимосвязь значений, относящихся к разным моментам времени.
Если значения ряда известны в отдельные моменты времени, то такой ряд называют дискретным , в отличие от непрерывного , значения которого известны в любой момент времени. Интервал между двумя последовательными моментами времени назовём тактом (шагом) . Здесь будут рассматриваться в основном дискретные временные ряды с фиксированной протяжённостью такта, принимаемой за единицу счёта. Заметим, что временные ряды экономических показателей, как правило, дискретны.
Значения ряда могут быть измеряемыми непосредственно (цена, доходность, температура), либо агрегированными (кумулятивными) , например, объём выпуска; расстояние, пройдённое грузоперевозчиками за временной такт.
Если значения ряда определяются детерминированной математической функцией, то ряд называют детерминированным . Если эти значения могут быть описаны лишь с привлечением вероятностных моделей, то временной ряд называют случайным .
Явление, протекающее во времени, называют процессом , поэтому можно говорить о детерминированном или случайном процессах. В последнем случае используют часто термин “стохастический процесс” . Анализируемый отрезок временного ряда может рассматриваться как частная реализация (выборка) изучаемого стохастического процесса, генерируемого скрытым вероятностным механизмом.
Временные ряды возникают во многих предметных областях и имеют различную природу. Для их изучения предложены различные методы, что делает теорию временных рядов весьма разветвленной дисциплиной. Так, в зависимости от вида временных рядов можно выделить такие разделы теории анализа временных рядов:
– стационарные случайные процессы, описывающие последовательности случайных величин, вероятностные свойства которых не изменяются во времени. Подобные процессы широко распространены в радиотехнике, метереологии, сейсмологии и т. д.
– диффузионные процессы, имеющие место при взаимопроникновении жидкостей и газов.
– точечные процессы, описывающие последовательности событий, таких как поступление заявок на обслуживание, стихийных и техногенных катастроф. Подобные процессы изучаются в теории массового обслуживания.
Мы ограничимся рассмотрением прикладных аспектов анализа временных рядов, которые полезны при решении практических задач в экономике, финансах. Основной упор будет сделан на методы подбора математической модели для описания временного ряда и прогнозирования его поведения.
1.Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
– описание характерных особенностей ряда в сжатой форме;
– построение модели временного ряда;
– предсказание будущих значений на основе прошлых наблюдений;
– управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
1) графическое представление и описание поведения ряда;
2) выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
3) исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
4) построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
5) прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
1) корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
2) спектральный анализ, позволяющий находить периодические составляющие временного ряда;
3) методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
5) методы прогнозирования.
2.Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.). Под детерминированной составляющей временного ряда
понимают числовую последовательность , элементы которой вычисляются по определенному правилу как функция времени t . Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом – плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
1) тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
2) сезонный эффект s , связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Рис. Структурные компоненты временного ряда.
Типичные примеры сезонного эффекта: изменение загруженности автотрассы в течение суток, по дням недели, временам года, пик продаж товаров для школьников в конце августа - начале сентября. Сезонная компонента со временем может меняться, либо носить плавающий характер. Так на графике объема перевозок авиалайнерами (см рис.) видно, что локальные пики, приходящиеся на праздник Пасхи «плавают» из-за изменчивости ее сроков.
Циклическая компонента c , описывающая длительные периоды относительного подъема и спада и состоящая из циклов переменной длительности и амплитуды. Подобная компонента весьма характерна для рядов макроэкономических показателей. Циклические изменения обусловлены здесь взаимодействием спроса и предложения, а также наложением таких факторов, как истощение ресурсов, погодные условия, изменения в налоговой политике и т. п. Отметим, что циклическую компоненту крайне трудно идентифицировать формальными методами, исходя только из данных изучаемого ряда.
«Взрывная» компонента i , иначе интервенция, под которой понимают существенное кратковременное воздействие на временной ряд. Примером интервенции могут служить события «черного вторника» 1994г., когда курс доллара за день вырос на несколько десятков процентов.
Случайная составляющая ряда отражает воздействие многочисленных факторов случайного характера и может иметь разнообразную структуру, начиная от простейшей в виде «белого шума» до весьма сложных, описываемых моделями авторегрессии-скользящего среднего (подробнее дальше).
После выделения структурных компонент необходимо специфицировать форму их вхождения во временной ряд. На верхнем уровне представления с выделением лишь детерминированной и случайной составляющих обычно используют аддитивную либо мультипликативную модели.
Аддитивная модель имеет вид
;мультипликативная –
3.3.1. Методы анализа и прогнозирования временных рядов
Модели стационарных и нестационарных временных рядов. Пусть Рассмотрим временной ряд X (t ). Пусть сначала временной ряд принимает числовые значения. Это могут быть, например, цены на батон хлеба в соседнем магазине или курс обмена доллара на рубли в ближайшем обменном пункте. Обычно в поведении временного ряда выявляют две основные тенденции - тренд и периодические колебания.
При этом под трендом понимают зависимость от времени линейного, квадратичного или иного типа, которую выявляют тем или иным способом сглаживания (например, экспоненциального сглаживания) либо расчетным путем, в частности, с помощью метода наименьших квадратов. Другими словами, тренд - это очищенная от случайностей основная тенденция временного ряда.
Временной ряд обычно колеблется вокруг тренда, причем отклонения от тренда часто обнаруживают правильность. Часто это связано с естественной или назначенной периодичностью, например, сезонной или недельной, месячной или квартальной (например, в соответствии с графиками выплаты заплаты и уплаты налогов). Иногда наличие периодичности и тем более ее причины неясны, и задача статистика - выяснить, действительно ли имеется периодичность.
Элементарные методы оценки характеристик временных рядов обычно достаточно подробно рассматриваются в курсах "Общей теории статистики" (см., например, учебники ), поэтому нет необходимости подробно разбирать их здесь. О некоторых современных методах оценивания длины периода и самой периодической составляющей речь пойдет ниже в подразделе 3.3.2.
Характеристики временных рядов. Для более подробного изучения временных рядов используются вероятностно-статистические модели. При этом временной ряд X (t ) рассматривается как случайный процесс (с дискретным временем). Основными характеристиками X (t ) являются математическое ожидание X (t ), т.е.
дисперсия X (t ), т.е.
и автокорреляционная функция временного ряда X (t )
![]()
т.е. функция двух переменных, равная коэффициенту корреляции между двумя значениями временного ряда X (t ) и X (s ).
В теоретических и прикладных исследованиях рассматривают широкий спектр моделей временных рядов. Выделим сначала стационарные модели. В них совместные функции распределения для любого числа моментов времени k , а потому и все перечисленные выше характеристики временного ряда не меняются со временем . В частности, математическое ожидание и дисперсия являются постоянными величинами, автокорреляционная функция зависит только от разности t - s. Временные ряды, не являющиеся стационарными, называются нестационарными.
Линейные регрессионные модели с гомоскедастичными и гетероскедастичными, независимыми и автокоррелированными остатками. Как видно из сказанного выше, основное - это "очистка" временного ряда от случайных отклонений, т.е. оценивание математического ожидания. В отличие от простейших моделей регрессионного анализа, рассмотренных в главе 3.2, здесь естественным образом появляются более сложные модели. Например, дисперсия может зависеть от времени. Такие модели называют гетероскедастичными, а те, в которых нет зависимости от времени - гомоскедастичными. (Точнее говоря, эти термины могут относиться не только к переменной "время", но и к другим переменным.)
Далее, в главе 3.2 предполагалось, что погрешности независимы между собой. В терминах настоящей главы это означало бы, что автокорреляционная функция должна быть вырожденной - равняться 1 при равенстве аргументов и 0 при их неравенстве. Ясно, что для реальных временных рядов так бывает отнюдь не всегда. Если естественный ход изменений наблюдаемого процесса является достаточно быстрым по сравнению с интервалом между последовательными наблюдениями, то можно ожидать "затухания" автокорреляции" и получения практически независимых остатков, в противном случае остатки будут автокоррелированы.
Идентификация моделей. Под идентификацией моделей обычно понимают выявление их структуры и оценивание параметров. Поскольку структура - это тоже параметр, хотя и нечисловой, то речь идет об одной из типовых задач прикладной статистики - оценивании параметров.
Проще всего задача оценивания решается для линейных (по параметрам) моделей с гомоскедастичными независимыми остатками. Восстановление зависимостей во временных рядах может быть проведено на основе методов наименьших квадратов и наименьших модулей оценивания параметров в моделях линейной (по параметрам) регрессии. На случай временных рядов переносятся результаты, связанные с оцениванием необходимого набора регрессоров, в частности, легко получить предельное геометрическое распределение оценки степени тригонометрического полинома.
Однако на более общую ситуацию такого простого переноса сделать нельзя. Так, например, в случае временного ряда с гетероскедастичными и автокоррелированными остатками снова можно воспользоваться общим подходом метода наименьших квадратов, однако система уравнений метода наименьших квадратов и, естественно, ее решение будут иными. Формулы в терминах матричной алгебры, о которых упоминалось в главе 3.2, будут отличаться. Поэтому рассматриваемый метод называется "обобщенный метод наименьших квадратов (ОМНК)".
Замечание. Как уже отмечалось в главе 3.2, простейшая модель метода наименьших квадратов допускает весьма далекие обобщения, особенно в области системам одновременных эконометрических уравнений для временных рядов. Для понимания соответствующей теории и алгоритмов необходимо владение методами матричной алгебры. Поэтому мы отсылаем тех, кому это интересно, к литературе по системам эконометрических уравнений и непосредственно по временным рядам , в которой особенно много интересуются спектральной теорией, т.е. выделением сигнала из шума и разложением его на гармоники. Подчеркнем еще раз, что за каждой главой настоящей книги стоит большая область научных и прикладных исследований, вполне достойная того, чтобы посвятить ей много усилий. Однако из-за ограниченности объема книги мы вынуждены изложение сделать конспективным.
Системы эконометрических уравнений. В качестве первоначального примера рассмотрим эконометрическую модель временного ряда, описывающего рост индекса потребительских цен (индекса инфляции). Пусть I (t ) - рост цен в месяц t (подробнее об этой проблематике см. главу 7 в ). По мнению некоторых экономистов естественно предположить, что
I (t ) = с I (t - 1) + a + bS (t - 4) + e , (1)
где I (t -1) - рост цен в предыдущий месяц (а с - некоторый коэффициент затухания, предполагающий, что при отсутствии внешний воздействий рост цен прекратится), a - константа (она соответствует линейному изменению величины I (t ) со временем), bS (t- 4) - слагаемое, соответствующее влиянию эмиссии денег (т.е. увеличения объема денег в экономике страны, осуществленному Центральным Банком) в размере S (t- 4) и пропорциональное эмиссии с коэффициентом b , причем это влияние проявляется не сразу, а через 4 месяца; наконец, e - это неизбежная погрешность.
Модель (1), несмотря на свою простоту, демонстрирует многие характерные черты гораздо более сложных эконометрических моделей. Во-первых, обратим внимание на то, что некоторые переменные определяются (рассчитываются) внутри модели, такие, как I (t ). Их называют эндогенными (внутренними). Другие задаются извне (это экзогенные переменные). Иногда, как в теории управления, среди экзогенных переменных, выделяют управляемые переменные - те, с помощью выбора значений которых можно привести систему в нужное состояние.
Во-вторых, в соотношении (1) появляются переменные новых типов - с лагами, т.е. аргументы в переменных относятся не к текущему моменту времени, а к некоторым прошлым моментам.
В-третьих, составление эконометрической модели типа (1) - это отнюдь не рутинная операция. Например, запаздывание именно на 4 месяца в связанном с эмиссией денег слагаемом bS (t- 4) - это результат достаточно изощренной предварительной статистической обработки. Далее, требует изучения вопрос зависимости или независимости величин S (t- 4) и I(t ) в различные моменты времени t . От решения этого вопроса зависит, как выше уже отмечалось, конкретная реализация процедуры метода наименьших квадратов.
С другой стороны, в модели (1) всего 3 неизвестных параметра, и постановку метода наименьших квадратов выписать нетрудно:
Проблема идентифицируемости. Представим теперь модель тапа (1) с большим числом эндогенных и экзогенных переменных, с лагами и сложной внутренней структурой. Вообще говоря, ниоткуда не следует, что существует хотя бы одно решение у такой системы. Поэтому возникает не одна, а две проблемы. Есть ли хоть одно решение (проблема идентифицируемости)? Если да, то как найти наилучшее решение из возможных? (Это - проблема статистической оценки параметров.)
И первая, и вторая задача достаточно сложны. Для решения обеих задач разработано множество методов, обычно достаточно сложных, лишь часть из которых имеет научное обоснование. В частности, достаточно часто пользуются статистическими оценками, не являющимися состоятельными (строго говоря, их даже нельзя назвать оценками).
Коротко опишем некоторые распространенные приемы при работе с системами линейных эконометрических уравнений.
Система линейных одновременных эконометрических уравнений. Чисто формально можно все переменные выразить через переменные, зависящие только от текущего момента времени. Например, в случае уравнения (1) достаточно положить
H (t ) = I (t- 1), G (t) = S (t- 4).
Тогда уравнение примет вид
I (t ) = с H (t ) + a + bG (t ) + e . (2)
Отметим здесь же возможность использования регрессионных моделей с переменной структурой путем введения фиктивных переменных. Эти переменные при одних значениях времени (скажем, начальных) принимают заметные значения, а при других - сходят на нет (становятся фактически равными 0). В результате формально (математически) одна и та же модель описывает совсем разные зависимости.
Косвенный, двухшаговый и трехшаговый методы наименьших квадратов. Как уже отмечалось, разработана масса методов эвристического анализа систем эконометрических уравнений. Они предназначены для решения тех или иных проблем, возникающих при попытках найти численные решения систем уравнений.
Одна из проблем связана с наличием априорных ограничений на оцениваемые параметры. Например, доход домохозяйства может быть потрачен либо на потребление, либо на сбережение. Значит, сумма долей этих двух видов трат априори равна 1. А в системе эконометрических уравнений эти доли могут участвовать независимо. Возникает мысль оценить их методом наименьших квадратов, не обращая внимания на априорное ограничение, а потом подкорректировать. Такой подход называют косвенным методом наименьших квадратов.
Двухшаговый метод наименьших квадратов состоит в том, что оценивают параметры отдельного уравнения системы, а не рассматривают систему в целом. В то же время трехшаговый метод наименьших квадратов применяется для оценки параметров системы одновременных уравнений в целом. Сначала к каждому уравнению применяется двухшаговый метод с целью оценить коэффициенты и погрешности каждого уравнения, а затем построить оценку для ковариационной матрицы погрешностей. После этого для оценивания коэффициентов всей системы применяется обобщенный метод наименьших квадратов.
Менеджеру и экономисту не следует становиться специалистом по составлению и решению систем эконометрических уравнений, даже с помощью тех или иных программных систем, но он должен быть осведомлен о возможностях этого направления эконометрики, чтобы в случае производственной необходимости квалифицированно сформулировать задание для специалистов по прикладной статистике.
От оценивания тренда (основной тенденции) перейдем ко второй основной задаче эконометрики временных рядов - оцениванию периода (цикла).
| Предыдущая |
Цель анализа временных рядов обычно заключается в построении математической модели ряда, с помощью которой можно объяснить его поведение и осуществить прогноз на определенный период времени. Анализ временных рядов включает следующие основные этапы.
Анализ временного ряда обычно начинается с построения и изучения его графика.
Если нестационарность временного ряда очевидна, то первым делом надо выделить и удалить нестационарную составляющую ряда. Процесс удаления тренда и других компонент ряда, приводящих к нарушению стационарности, может проходить в несколько этапов. На каждом из них рассматривается ряд остатков, полученный в результате вычитания из исходного ряда подобранной модели тренда, или результат разностных и других преобразований ряда. Кроме графиков, признаками нестационарности временного ряда могут служить не стремящаяся к нулю автокорреляционная функция (за исключением очень больших значений лагов).
Подбор модели для временного ряда. После того, как исходный процесс максимально приближен к стационарному, можно приступить к подбору различных моделей полученного процесса. Цель этого этапа – описание и учет в дальнейшем анализе корреляционной структуры рассматриваемого процесса. При этом на практике чаще всего используются параметрические модели авторегрессии-скользящего среднего (ARIMA-модели)
Модель может считаться подобранной, если остаточная компонента ряда является процессом типа «белого шума», когда остатки распределены по нормальному закону с выборочным средним равным 0. После подбора модели обычно выполняются:
оценка дисперсии остатков, которая в дальнейшем может быть использована для построения доверительных интервалов прогноза;
анализ остатков с целью проверки адекватности модели.
Прогнозирование и интерполяция . Последним этапом анализа временного ряда может быть прогнозирование его будущих (экстраполяция) или восстановление пропущенных (интерполяция) значений и указания точности этого прогноза на базе подобранной модели. Не всегда удается хорошо подобрать математическую модель для временного ряда. Неоднозначность подбора модели может наблюдаться как на этапе выделения детерминированной компоненты ряда, так и при выборе структуры ряда остатков. Поэтому исследователи довольно часто прибегают к методу нескольких прогнозов, сделанных с помощью разных моделей.
Методы анализа. При анализе временных рядов обычно используются следующие методы:
графические методы представления временных рядов и их сопутствующих числовых характеристик;
методы сведения к стационарным процессам: удаление тренда, модели скользящего среднего и авторегрессии;
методы исследования внутренних связей между элементами временных рядов.
3.5. Графические методы анализа временных рядов
Зачем нужны графические методы. В выборочных исследованиях простейшие числовые характеристики описательной статистики (среднее, медиана, дисперсия, стандартное отклонение) обычно дают достаточно информативное представление о выборке. Графические методы представления и анализа выборок при этом играют лишь вспомогательную роль, позволяя лучше понять локализацию и концентрацию данных, их закон распределения.
Роль графических методов при анализе временных рядов совершенно иная. Дело в том, что табличное представление временного ряда и описательные статистики чаще всего не позволяют понять характер процесса, в то время как по графику временного ряда можно сделать довольно много выводов. В дальнейшем они могут быть проверены и уточнены с помощью расчетов.
При анализе графиков можно достаточно уверенно определить:
наличие тренда и его характер;
наличие сезонных и циклических компонент;
степень плавности или прерывистости изменений последовательных значений ряда после устранения тренда. По этому показателю можно судить о характере и величине корреляции между соседними элементами ряда.
Построение и изучение графика. Построение графика временного ряда – совсем не такая простая задача, как это кажется на первый взгляд. Современный уровень анализа временных рядов предполагает использование той или иной компьютерной программы для построения их графиков и всего последующего анализа. Большинство статистических пакетов и электронных таблиц снабжено теми или иными методами настройки на оптимальное представление временного ряда, но даже при их использовании могут возникать различные проблемы, например:
из-за ограниченности разрешающей способности экранов компьютеров размеры выводимых графиков могут быть также ограничены;
при больших объемах анализируемых рядов точки на экране, изображающие наблюдения временного ряда, могут превратиться в сплошную черную полосу.
Для борьбы с этими затруднениями используются различные способы. Наличие в графической процедуре режима «лупы» или «увеличения» позволяет изобразить более крупно выбранную часть ряда, однако при этом становится трудно судить о характере поведения ряда на всем анализируемом интервале. Приходится распечатывать графики для отдельных частей ряда и состыковыватьих вместе, чтобы увидеть картину поведения ряда в целом. Иногда для улучшения воспроизведения длинных рядов используетсяпрореживание, то есть выбор и отображение на графике каждой второй, пятой, десятой и т.д. точки временного ряда. Эта процедура позволяет сохранить целостное представление ряда и полезна для обнаружения трендов. На практике полезно сочетание обеих процедур: разбиения ряда на части и прореживания, так как они позволяют определить особенности поведения временного ряда.
Еще одну проблему при воспроизведении графиков создают выбросы – наблюдения, в несколько раз превышающие по величине большинство остальных значений ряда. Их присутствие тоже приводит к неразличимости колебаний временного ряда, так как масштаб изображения программа автоматически подбирает так, чтобы все наблюдения поместились на экране. Выбор другого масштаба на оси ординат устраняет эту проблему, но резко отличающиеся наблюдения при этом остаются за границами экрана.
Вспомогательные графики. При анализе временных рядов часто используются вспомогательные графики для числовых характеристик ряда:
график выборочной автокорреляционной функции (коррелограммы) с доверительной зоной (трубкой) для нулевой автокорреляционной функции;
график выборочной частной автокорреляционной функции с доверительной зоной для нулевой частной автокорреляционной функции;
график периодограммы.
Первые дваиз этих графиков позволяют судить о связи (зависимости) соседних значений временного рада, они используются при подборе параметрических моделей авторегрессии и скользящего среднего. График периодограммы позволяет судить о наличии гармонических составляющих во временном ряде.
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.
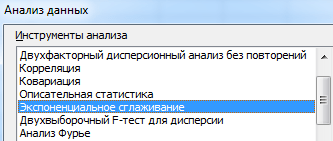
Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».

Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:
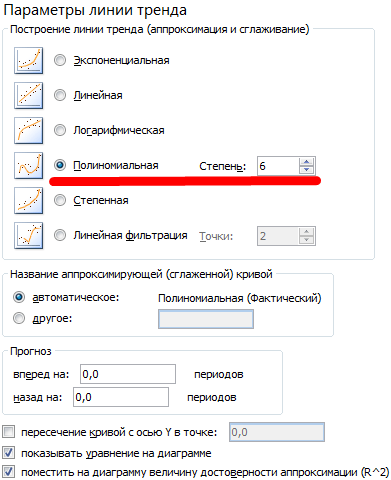
Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.
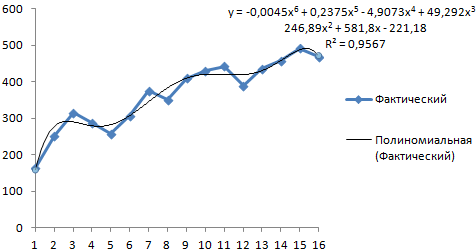
R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.

Получаем достаточно оптимистичный результат:

В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.

Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
Онлайн калькуляторы